
こんにちは。朝日ネット社員のjiweenです。 今日もデザインパターンを分析します。
今回は、データとその処理を分離して扱うパターンが3つ(Iterator, Visitor, Observer)登場します。ここでは、第2回で説明した「データと振る舞いの一体化は強制されない」ということを思い出してください。どのパターンでもデータと振る舞いが本質的に別の流動性を持っており、そのため自然と分離が起こります。
- 第1回 はじめに, 概要
- 第2回 結論
- 第3回 Adapter, State, Strategy, Abstract Factory
- 第4回 Template Method, Factory Method, Bridge, Proxy, Composite, Interpreter, Decorator
- 第5回 Visitor, Observer, Iterator, Facade, Mediator
- 第6回 Builder, Singleton, Prototype, Flyweight, Chain of Responsibility, Command, Memento, まとめ
目次(第5回)
- 目次(第5回)
- データ構造の走査をカプセル化するパターン
- "データ" と "データに対する処理" を多相化するパターン
- 振る舞いの実行タイミングと処理内容を動的にするパターン
- 依存関係をオブジェクト化するパターン
- 次回予告
データ構造の走査をカプセル化するパターン
- Iterator
Iterator
言わずと知れたパターンです。様々な言語に様々な形で標準実装され、私達の生活の一部となりました。プログラマが生まれたときに産声を上げるのはIteratorパターンの有り難みに涙しているからだと言われています1。
Iterator パターンにはバリエーションがありますが、ここでは Internal Iterator と呼ばれるものを取り上げます。Internal Iterator は External に対してより汎用であり、 Internal から External へ変形することは簡単です。
目的
Iteratorパターンは、 繰り返し処理(iteration)を表現するデザインパターン です。このパターンを使うことで、繰り返し処理を "データ構造の走査" と "走査時の処理" に分離 することができます。
また、繰り返し処理に関する実装の一部を共通化できます。
繰り返し処理はプログラミングにおいて非常に頻繁に現れるため、このパターンの適用によって大きな恩恵が得られます。
構造

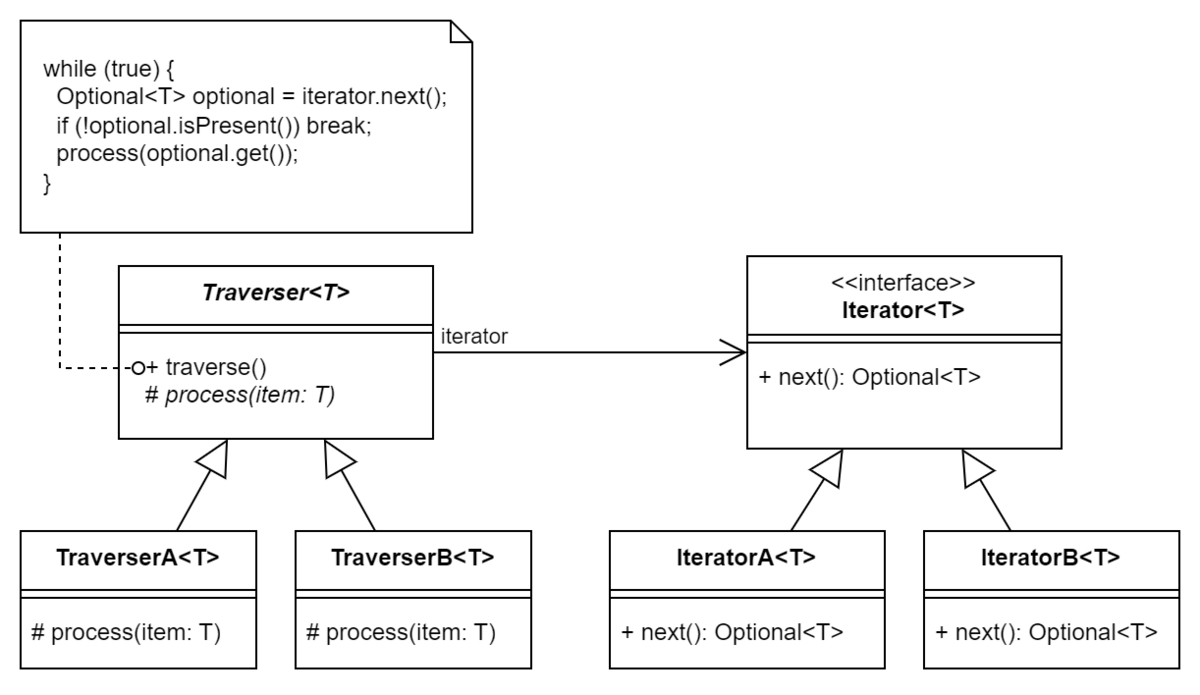
- これはJavaのGenerics機能を使用した場合の一例です
Iterable(GoF本ではAggregate) というインターフェイスが併用されることもありますが、ここでは省略しています
導出
(Internal) Iteratorパターンは以下のように導出されます。
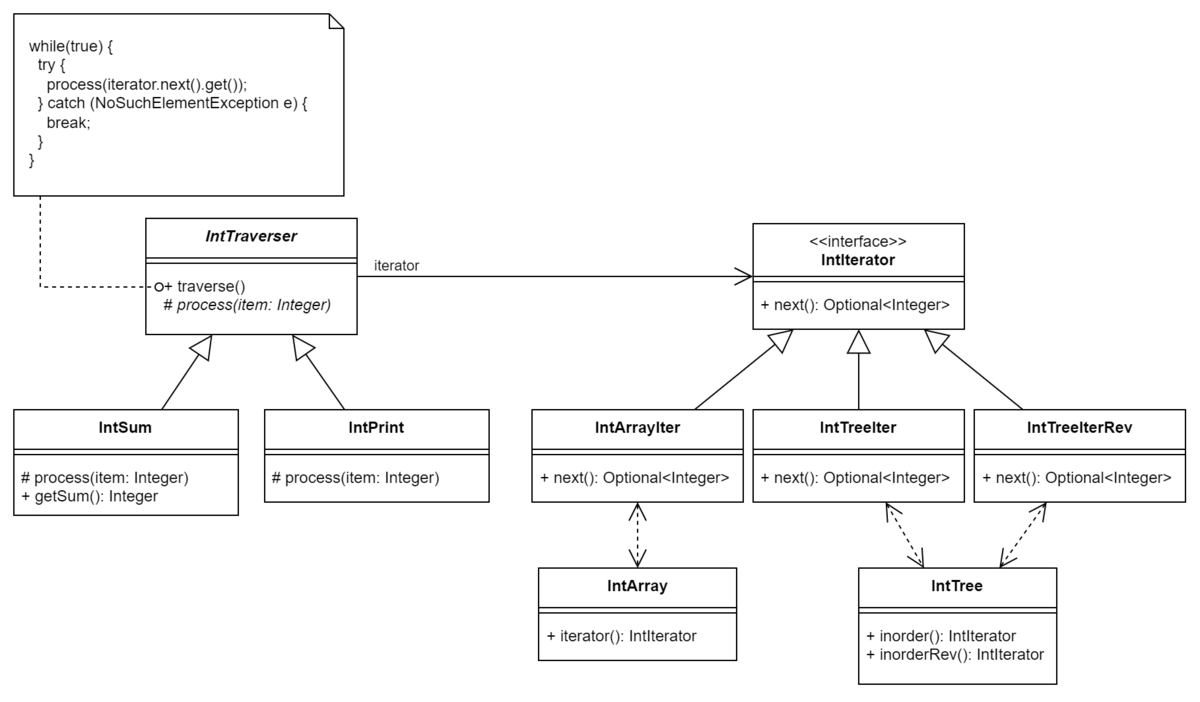
- 以下の2つのデータ構造があるとします。
IntArray:Integerの値の配列IntTree:Integerの値の木構造
- これらのデータ構造に対して、以下のような処理をサポートしたいとします。
IntArraySum:IntArrayのInteger値の合計を計算するIntArrayPrint:IntArrayのInteger値を標準出力に出力するIntTreeSum:IntTreeのInteger値の合計を計算するIntTreePrint:IntTreeのInteger値を標準出力に出力する- 正確には、木構造の中間順 (inorder) で
IntTreePrintRev:IntTreeのInteger値を、 逆順で 標準出力に出力する- 正確には、木構造の中間順 (inorder) の逆順で
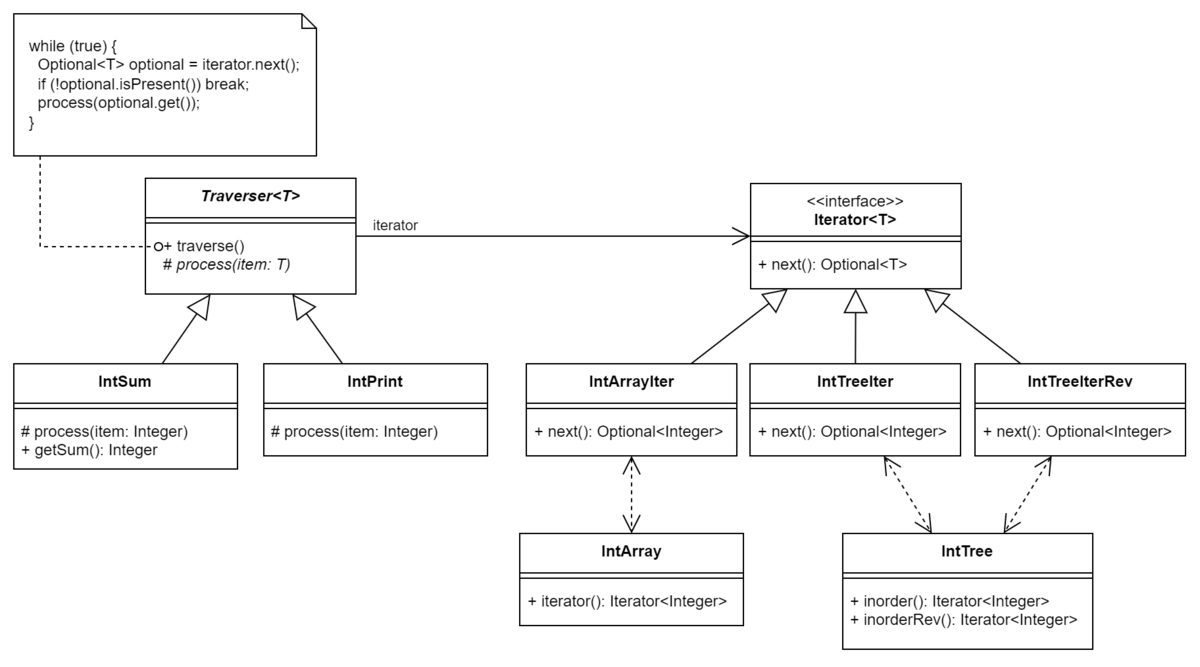
- "走査" の抽象化である
IntIteratorを定義します。どの処理も「Integer型の値を繰り返し取得する」という点において共通しており、取得先のデータ構造がIntArrayでもIntTreeでもそれは変わりません。つまり「Integer型の結果を繰り返し取得し、返す」というインターフェイスを定義することで、実際のデータ構造へのアクセスはカプセル化することができます。このカプセル化の1つの方法としては、IntIteratorというインターフェイスを定義し、 "次の値" を返すnextメソッドを定義します。ただしnextメソッドは終端に到達すると失敗するので、Optional<Integer>を返すようにします。IntIteratorは、Integer値を持つデータ構造に対する "走査" を表現していると言えます。


補足:
IntIteratorを定義したことでIntArraySum,IntTreeSumは同じ処理になるため、IntSumにまとめられます。同様に、IntArrayPrint,IntTreePrint,IntTreePrintRevはIntPrintにまとめられます。nextの戻り値にOptional<T>(T型の値か無効値を保持できるオブジェクト) を使用しましたが、終端に到達したら例外を返すという設計も考えられます。あるいは、例外ではなくnullを返し、終端に到達したかどうかは別のメソッドisDoneで判定させる (そうしないとnull値が入っていた場合と終端への到達が区別できないため)、という設計も考えられます。- nullを使う方法はあまり推奨されません。そもそも、Javaと異なり参照型のデフォルトがnull許容ではない言語 2 もあります。
"走査時の処理" の抽象化である
IntTraverserを定義します。IntTraverserには「繰り返し生成されるInteger型の値を使って何かの処理をする」という部分をカプセル化するのですが、このカプセル化の方法にも選択肢があります。例えば:- そもそも
IntTraverserによるカプセル化を行わない。クライアントに直接nextを呼び出させ、処理を記述させる。(これは External Iterator パターンになる) IntTraverserを抽象クラスとし、「何かの処理」をサブクラスに実装させる。IntTraverserは具象クラスとし、「何かの処理」は関数としてIntTraverserに渡す。- 後ほどVisitorパターンで説明する「クロージャ」 (ラムダ式など) を使えばこの方法は簡単です。
- そもそも
- ここでは、伝統的なオブジェクト指向ライクな方法である、サブクラスを使った方法を使用します。サブクラスでは、
Integerの値を受け取って何か処理をするメソッドprocessを定義します。


補足:
IntTraverserはIntIteratorをprivateで所持します。このため、IntTraverserはインターフェイスとしてでなく抽象クラスとして定義されています。結果としてクラス継承が発生していますが、IntTraverserがとても小さく、またiteratorがprivateとして隠蔽されているためほとんど問題になりません。しかし、このクラス継承につけ込んでこれ以上クラス階層を深くしたり状態を書き加えたりしないよう注意するべきです。
更に、繰り返すことができるデータの型は
Integerだけではありません 。私たちはIntIteratorとIntTraverserというインターフェイスを作りましたが、Integer型ではなくSomeType型のデータが現れたらSomeTypeIteratorとSomeTypeTraverserを作るのでしょうか?もちろんそうではありません。 Iterator/Traverser インターフェイスの記述においてそれがInteger型かSomeType型かは重要ではなく、どちらでも同じ記述になります。つまり、JavaのGenerics機能を使うと、Iterator<T>,Traverser<T>を書くことができます。

この設計方針だと、「IntTree の Integer 値を、 逆順で 標準出力に出力する」のクライアントコードは例えば次のようになります。
IntTree tree = createTree();
Traverser<Integer> printer = new IntPrint(tree.inorderRev());
printer.traverse();
- 実装全体が気になる人はぜひ実装してみてください。良い練習になると思います。
ここで述べた例は非常に簡単なものです。しかし、処理を繰り返すというこの汎用的なパターンはもっとたくさんのことに適用することができます。
(Internal) Iteratorパターンではデータ構造の走査についての詳細をクライアントからカプセル化できます。余計な流動性が分離されることで、クライアントは自身の流動性の記述により集中できるようになるでしょう。この流動性の向上は局所的には些細なものに見えるかもしれませんが、Iteratorパターンは (Generics等を使ってうまく書けば) 広範なコードに一度に適用できるため、総合的にはメリットが大きいです。
コードを書くときの体験としても、頻出する繰り返し処理という概念を抽象化できるので「書くのが楽だ」と感じるでしょう。例えば、Iteratorが無ければ繰り返しデータのちょっとした変換でも毎回for文を書かなければいけません。しかし、そのような変換はIteratorからIteratorへの変換として簡単に書けます。Rustではこれが標準ライブラリに実装されているので良い例になると思います。RustにおけるIteratorの使用例を見てみてください。
fn main() { let sum: u32 = (1..10) // 1, ..., 9 .zip((1..10).skip(1)) // (1, 2), (2, 3), ..., (9, 10) .map(|(a, b)| a * b) // 2, 6, ..., 90 .filter(|x| x % 3 == 0) // 3の倍数だけ残す .sum(); // 合計 println!("{}", sum); // 162 }
このようなコーディング体験はIteratorパターンが広まった大きな理由だと思います。
広告: このモジュラーな書き心地を非常に気に入って、どこでも使いたいとさえ思いますか?そんなあなたに関数型言語はどうでしょう。
Iteratorからデータ構造への特権的アクセス
Iteratorパターンでは、データ構造の走査という、データ構造の内部表現に関わる処理が別のオブジェクトに分離されます。 結果としてオブジェクトをまたいだデータの密結合が発生します。 (GoF本でも、Iteratorはデータ構造の内部データに対する特権的アクセスを持つ場合がある、と言及されています)
これはデータのカプセル化を破壊しているので心配になるかもしれません。
しかし、ここではデータのカプセル化よりIteratorのカプセル化を優先したというだけです。 データのカプセル化は第一目標ではありません。
"データ" と "データに対する処理" を多相化するパターン
Visitor
Visitorパターンはかなり普遍的なパターンの一つで、"オブジェクト" という単位への理解度を高めてくれます。Visitorパターンの構造を知るとデータと振る舞いをオブジェクトにどう振り分けるかは意外に自由だということが分かります。
個人的にVisitorパターンの習得はGoFデザインパターンの中で最も概念的に難しいと思います。「関係するデータと振る舞いを1つのオブジェクトにまとめる」というオブジェクト指向のありがちな傾向を真に受けると、最も不自然に見えるパターンだからです。しかし、このパターンはオブジェクト指向の拡張可能性を示唆しています。Visitorパターンを知ることでオブジェクト指向の射程距離を大きく伸ばすことができます。
目的
Visitorパターンは多相な (型が流動的な) データから多相な振る舞いを分離するパターンです。データと振る舞いが別の多相性を持ちます。
特に、データと振る舞いの静的な対応、つまり 型安全性 を保ったまま多相化できることが重要です。
構造


導出
多相性を含むデータを仮定します。 ここでは木構造データを実装する典型的なCompositeパターンを考えましょう。 データ構造の各要素はElementとして抽象化されますが、実際には色々な具象クラスになる可能性があります ("容器"だったり"中身"だったりする) 。
このような多相なデータ構造に依存する処理を追加しようと思った場合、Elementが持つメソッドとして定義するのがオブジェクト指向らしい素直な発想だと思われるでしょう。 するとElementインターフェイスにメソッドを追加し、サブクラスそれぞれについてメソッドを実装する必要があります。 これは、Elementに対する処理を要求するクライアントが1つしかないうちはさほど問題ありません。
しかし、様々なクライアントが求める様々な処理があったとしましょう。それらを全てElementに追加したいでしょうか? 処理を追加するごとにElementのサブクラス全ての変更が発生し、各サブクラスには色々なクライアントの求める雑多なメソッドが実装されていきます。
つまり Element自身が元から持つデータ構造としての流動性 (多相性) に加えて、クライアントからの要求処理という流動性が混ざってしまっています。 この場合、データ構造についての処理 (データ構造の振る舞いだったもの) はデータ構造から分離されるべきなのです。
そこでまずElementに対する処理を抽象化し、Visitorインターフェイスとして分離します。ここにデータ構造についての処理の流動性をカプセル化していきます。 VisitorはElementの具体クラス全てに対する処理を実行できなければならないので、Elementのサブクラスの数だけ対応するメソッドを持ちます。

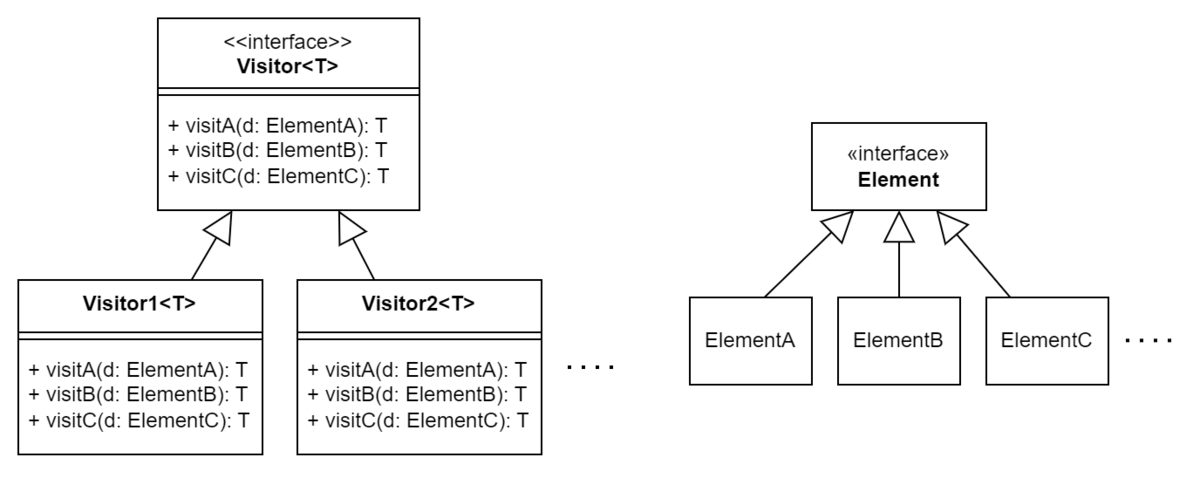
このVisitorの処理を実際に要素に対して適用するにはどうすればいいでしょう?ここがVisitorパターンのすごいところで考えどころなのですが、説明がややこしいので結論から言ってしまいます。
次のようにします。


interface Visitor<T> { T visitA(ElementA a); T visitB(ElementB b); // ... } interface Element { <T> T accept(Visitor<T> visitor); } class ElementA implements Element { @Override public <T> T accept(Visitor<T> visitor) { return visitor.visitA(this); } } class ElementB implements Element { @Override public <T> T accept(Visitor<T> visitor) { return visitor.visitB(this); } } // ElementC以降も同様
Element インターフェイスにVisitor (訪問者) を受け入れる accept メソッドを定義します。 Element のサブクラスは自分に適した処理を選択し、自分を渡してその処理を呼び出すような accept を実装します。
なぜこのようになるのでしょうか?
まず行いたい処理には Visitor と Element 両方の多相性が入り込むことに注意してください。つまり「どんな処理を行うか」という Visitor 側の多相性と「どんなデータに対して行うか」という Element 側の多相性です。 Visitor の処理を呼び出すと Visitor 側の多相性は解決されますが、 Element 側の多相性は未解決です。Visitorは多相な Element を渡された時、具体的にどの Element サブクラスに対して処理を行えばいいか知りません。
この多相性を解決するまともな方法はもちろん、今まで通り、インターフェイスを使うことです。(型安全性を保つためにも!)
今まで多相性 (型の流動性) を実現するためにインターフェイスを使ってきましたが、やってきたことを丁寧に言い直すと「インターフェイスのメソッドを呼び出した時に対応する実装が動的に呼び出されること (動的ディスパッチ) を利用して多相性を実現する」ということになります。つまり Visitor の処理を呼び出した時点で Visitor についての動的ディスパッチは起きており、あとは Element についての動的ディスパッチを引き起こす必要があります。 Element 側に、 Visitor が持っている複数の処理から目的のものを選択させるのです。この「選択を行う」メソッドがまさに accept メソッドで、 Element は Visitor オブジェクトを渡されると複数の処理のなかから自分に対応した処理を呼び出します。
これでめでたくVisitorパターンの完成です!
Visitor の処理に Element の多相性が入り込むことを考えるとこのような設計が自然と出てくることが分かるのですが、なかなか気づきにくい発想です。
VisitorからElementへの特権的アクセス
Iteratorパターンと同様、Visitorパターンではデータのカプセル化よりも他のカプセル化 (多相化) が優先されるため、VisitorがElementに対するデータアクセス権を持つこともあります。
特にVisitorパターンでは、データと振る舞いが互いから見て多相になるという意味でかなり疎結合な一方、特権的アクセスも可能だというのは不思議な設計に感じます。
しかし型上の結合と値上の結合はある程度独立した問題です。 Vistorパターンのケースは「型レベルで疎結合 (多相) にする必要があったが値レベルではむしろ密結合するかもしれない」と説明することができます。
型安全性
Visitorパターンは具体的にどういう意味で型安全なのでしょうか?型の恩恵はいくつもありますが、Visitorパターンで特有なのはElementの多相性に対する安全性です。
それは、 ElementA, ElementB に加えて ElementC を増やしたときを考えると分かります。 ElementC の accept の実装は強制されていますが、それを書き始めたところで visitC が未定義であることにすぐ気づきます。 visitC をVisitorに書き加えて、それを全ての Visitor サブクラスで実装するまでコンパイルは通りません。
もし accept の仕組みが無く、Elementの型を見て処理を分岐していたとしたらどうでしょうか?
if (element.isA()) { return visitor.visitA(d); } else if (element.isB()) { return visitor.visitB(d); } else { error("wow"); }
ElementC を増やして、 Visitor の変更を忘れたとしてもそのままコンパイルを通せてしまいます。 Element の全ケースを Visitor で処理できることが期待されていますが、実際には ElementC を処理できず、バグ (実行時エラーや意図しない動作) が発生するでしょう。
直和型によるVisitorパターンの代替
上で紹介したように、Visitorパターンを用いなくても、型判定を書くことでElementの多相性を解決する方法もあります。この方法はコードの見た目は直感的ですが、実行するまでエラーを検出できないのでした。
しかし、もし言語が直和型 (と直和型に対する型安全なパターンマッチ) と呼ばれるものをサポートしていれば、似たような書き方でも型安全性を保つことができます。安全なだけでなく局所的なコードで簡潔に多相性を解決できるので、Visitorパターンより使い勝手が優れています。
本記事では直和型についてこれ以上詳しく説明しません。しかし 直和型はVisitorパターンにある意味等価であることが知られており3、直和型があればそれを使うのが最も直接的なアプローチになるでしょう。このような強力な型システムは、関数型プログラミングだけでなくオブジェクト指向プログラミングにおいても有用です。
クロージャでVisitorパターンの制限を取り除く
もしあなたが直和型と直和型のパターンマッチに恵まれし者であればここを読む必要はありません。万歳!
さて、ここまでの基本的なVisitorパターンの議論はまだ課題を残しています。Element (データ構造) とVisitor (その振る舞い) をきれいに分離することはできましたが、Visitor (振る舞い) を他のオブジェクトと結合させる時に制限があります。
(直和型+パターンマッチではこのような制限はありません)
具体的には、あるオブジェクトの実装において、ある多相なデータに対する処理が複数あるという場合です。処理が1つしか無ければオブジェクトにそのままVisitorを実装させればよいのですが、複数の処理がある場合、複数のVisitorインターフェイスを1つのオブジェクトで実装することはできないためそれは不可能です。
もちろん密結合を諦めればこの問題は回避できます。それぞれの処理を別のVisitorに分ければ良いのです。しかし、Visitorの実装が元のオブジェクトの内部コンテキスト (プライベートフィールドやプライベートメソッド、ローカル変数など) に強く依存している場合、この回避策はコードを無駄に複雑にします。本来オブジェクトの中だけで済ませられるはずだったローカルなコンテキストをVisitorから使えるように変更しなければなりません。
これは1つ目の流動性に関するルールで述べた「無闇にオブジェクトを細分化しない」という方針に反する可能性があります。流動性以外の理由でオブジェクト分割のコストを払わされているからです。
問題点は、 Visitorを元のコンテキストから離れた場所で定義しなければならないこと と、 元のコンテキストと連携するための手間がかかること です。つまり、元のコンテキストの上でVisitorを定義し、元のコンテキストの上で実行させることができれば問題は解決されます。このような、定義時の環境で実行される関数は一般にクロージャと呼ばれます。クロージャは、Javaでは匿名クラスによって書くことができます。
少し伝わりづらいと思うのでコード全体を載せます。
interface Element { <T> T accept(Visitor<T> visit); } class ElementA implements Element { @Override public <T> T accept(Visitor<T> visit) { return visit.visitA(this); } } class ElementB implements Element { @Override public <T> T accept(Visitor<T> visit) { return visit.visitB(this); } } interface Visitor<T> { T visitA(ElementA d); T visitB(ElementB d); } class Client { Element something() { return new ElementB(); } int someContext() { return 3; } void process() { Element element = something(); String s = element.accept(new Visitor<String>() { public String visitA(ElementA d) { return "d is ElementA, context = " + someContext(); } public String visitB(ElementB d) { return "d is ElementB, context = " + someContext(); } }); System.out.println(s); } } class Program { public static void main(String[] args) { (new Client()).process(); } }
このコードでは、Visitorの処理を書く時にClientのコンテキストに依存することができます。
気をつけなければならないのは、匿名クラスはフィールド変数を持ててしまうことです。匿名クラスにフィールド変数を持たせるのは、ただでさえ複雑化しやすい "プログラムの状態" を更に追いづらくするのでおすすめしません。
こういった危険性を視界から消すために、匿名クラスをラムダ式のような関数オブジェクトで代替したくなるかもしれません。関数オブジェクトは抽象メソッドを1つしか持てないので、 accept メソッドは Element サブクラスの数だけ関数オブジェクトを受け取ることになります。しかし、これをJavaで書くと構文的な理由で少し煩雑になるので、総合的に見るとむしろ匿名クラスの方がコードが分かりやすいと思います。
振る舞いの実行タイミングと処理内容を動的にするパターン
- Observer
Observer
目的
Observer (観察者) パターンは振る舞いの実行タイミングと詳細な処理内容とを別のオブジェクトに分離し、それらの紐づけを実行時に決められるようにします。紐づけが静的に決まる場合は単にメソッドを書いて呼び出すだけですが、このパターンを使うと紐づけを実行時レベルで (=動的に) 決定できます。
このパターンは イベント駆動プログラミング という形で広く応用されており、様々な言語・ライブラリ・フレームワークで類似したパターンを見ることができます。Observerパターンは原初のイベント駆動プログラミングです。
構造

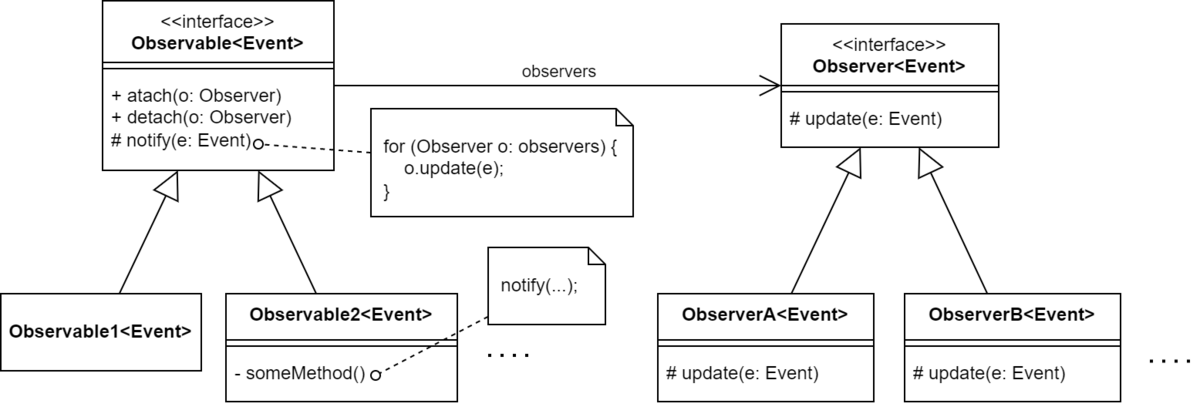
導出
処理内容と実行タイミングの分離は、その対応が静的に決まっている場合はメソッドを普通に使うだけで行なえます。つまりメソッドの中身が処理内容の記述にあたり、メソッドの呼び出しが実行タイミングの記述にあたります。
class SomeClass { void process() { // 処理の内容と } void caller() { // ... // 実行タイミングは別! process(); // ... } }
ただし Observerパターンでは処理内容が動的に追加・削除できることが重要です。よって処理=メソッド自体をオブジェクトとして扱い、そのコレクション ("処理"オブジェクトが集まったオブジェクト) を表現する必要があります。これが observers フィールドです。
基本的なアイデアはこれだけです。
Observerパターンでは、"処理"オブジェクトは何かのイベント発生を待っていることから observer (観察者) と呼ばれます。 Observable の attach メソッドは、 Observable のイベントを観察する Observer オブジェクトを observers に追加します。 detach で削除することもできます。 Observable のサブクラスでは、何かが起きたら notify メソッドを呼び出します。 notify の中では observers に登録された Observer オブジェクトたちに対して update メソッドを呼び出します。
observers の所持という共通性を実装するため、 Observer は (インターフェイスではなく) 抽象クラスになっています。 observers は必ずprivateにしておきましょう。
Visitorパターンの時と同様に、Observer を匿名クラスや関数オブジェクトで書くこともできます。つまりクロージャが使えるということです。
Visitorパターンとの比較
振る舞いの実行を他のオブジェクトに移譲しているという点でVisitorパターンと似ているので混乱するかもしれません。Observerパターンでは、可変個の振る舞いの呼び出しが動的に移譲され、実行タイミングが制御されます。 Visitorパターンでは実行タイミングの制御ではなく多相性の解決のために呼び出しの移譲をしているだけなので、一回の呼び出しを一時的に移譲するだけです。
逆に、Visitorパターンでは振る舞いから見たデータが多相であることが重要ですが、Observerパターンにそのような要件はありません。
複数のObservable
上図のような設計では1つのオブジェクトが複数の Observable として振る舞いたい場合にクラスの多重継承が必要になりますが、クラスの多重継承はJavaなどでは禁止されています (安全性と両立できないため)。
この問題はVisitorと同じく、クロージャで解決するか、クラスの分割で回避することができます。
VisitorやObserverに限りませんが、クロージャを使用することで、型レベルで分離したクラスを実装上においては密結合させることができるのです。
依存関係をオブジェクト化するパターン
- Facade
- Mediator
依存関係自体を流動的要素として扱うパターンです。依存関係が実際に変更されやすい要素である場合はこれらのパターンはもちろん有用です。しかし、そうでなくとも依存関係というものは厄介で、容易に複雑化し人を悩ませる傾向があります。依存関係が複雑に見え始めた時、それは依存関係を流動的要素とみなすべき時かもしれません。
Facade
Facadeパターンはオブジェクト群を使用するための簡略化された窓口 (表構え=facade) を提供し、それによってオブジェクト群を特定の目的に特化させます。典型的には、Facadeクラスはデータを持たず、他の複数のオブジェクトを"関連"ではなく"依存"によって使用する何らかの振る舞いを持ちます。


パターンの厳密な定義はさておき、このパターンの構造は他にもバリエーションが考えられます。FacadeがClassAやClassBに対して持つ関係は"依存"ではなく"関連"になる場合もあるでしょうし、また必ずしも複数のオブジェクトに依存するとは限りません。
Facadeパターンは単に「他のオブジェクトの簡素な窓口となるオブジェクトを定義する」という目的で特徴づけられるパターンであり、パターン自体に深い意味はないと思います。深い意味はありませんが、無意味ではありません。このパターンからは、 直接的な依存先を不必要に大きくしたり増やしたりすべきでない ということを学ぶことができます。(ここでの"依存"はUMLクラス図の"依存"より広い意味で言っています)
良識的なプログラマにとってはもう当たり前過ぎて忘れてしまったかもしれませんが、あるモジュールをプログラミングするために一度にたくさんの知識や思考を要求するような、つまり直接的な依存が多いモジュールは好ましくありません。これまでの言葉で言い直すと、オブジェクトは判別しうる限り最小限の流動的要素を担当しているべきです。さもなければ人間は一度の変更で色々な影響を気にせねばならず大変だからです。そういった依存の多いオブジェクトを見たらFacadeパターンを思い出しましょう。Facadeは細部の依存を覆い隠し、目的に特化したより簡単なオブジェクトに見せかけます。Facadeはわざわざパターンとして使うことは少ないかもしれませんが 依存を減らすべきだ というとても基本的なことを教えてくれます。
SOLID原則の第4項「インターフェイス分離の原則」も、不必要な依存は遠ざけておくべきだという主旨のことを言っています。4
Adapterパターンとの関係
意図された目的が異なります。Adapterパターンは実装の共通化に使用され、Facadeパターンは依存の簡素化に使用されます。しかし、「基礎的な実装とそれを特化させる実装を分離する」という意味ではあまり違いがありません。
実装上の違いも厳密ではないかもしれませんが、通常、Adapterパターンが1つのクラスに対するstatefulな (状態を伴った) 変換であるのに対し、Facadeパターンは複数のクラスに対するstatelessな変換です。
Mediator
Mediatorは 相互に関係する過密な依存関係をオブジェクトとみなす パターンです。
n個のクラスの間の依存関係を考えます。依存関係の数がnについて線形より大きいオーダーで増える設計であれば、それは設計に失敗している可能性が高いです (最も悪い場合では、あるクラスが他の全てのクラスを知っているというn2オーダーの依存になります)。新しいクラスを追加したときに発生する依存関係が定数個で抑えられないことを意味するからです。
このような依存関係を適切に扱う方法は、複雑な依存関係を仲裁するクラス (Mediator) を導入することです。n個のクラスは互いに直接依存することなく、仲裁役のクラスに依存するようになります。各クラスがMediatorとだけ依存し合うので依存関係の数はnに対して線形オーダーになります。 そして、複雑な依存関係は少なくともMediatorの中にカプセル化されます。

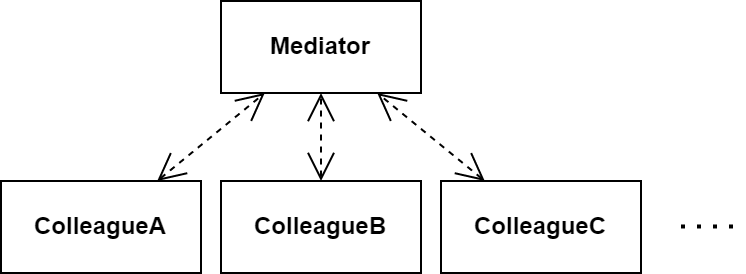
(インターフェイスが導入されるかは場合によると思うので省いています)
次回予告
一見難解なVisitorパターンに含まれる単純な目的が伝わったでしょうか?私は初めてこのパターンを理解した時踊らずにはいられませんでした。
第5回は以上です。ここまでで有益な (と判断した) パターンについては説明し終わりました。最終回となる第6回では、SingletonパターンとBuilderパターンの有用性について議論します。また、残りの重要性の低いパターンを簡単に説明します。
採用情報
朝日ネットでは新卒採用・キャリア採用を行っております。


- 諸説あります。↩
- このような性質は、 void safety, null safety, null安全性 などと呼ばれます。 https://en.wikipedia.org/wiki/Void_safety↩
- https://blog.ploeh.dk/2018/06/25/visitor-as-a-sum-type/↩
- https://en.wikipedia.org/wiki/Interface_segregation_principle↩