
はじめに
開発部の ikasat です。
皆さんは git, ssh, rsync のような外部コマンドを呼び出すスクリプトを書きたくなったことはありますか?
個人的にこの類のスクリプトは最初はシェルスクリプトとして書くのですが、改修を重ねるうちに肥大化して処理も複雑になり、
後から Python のような汎用プログラミング言語で書き直すことがよくあります。
外部コマンド呼び出しを書き直す際に、Git 操作のために pygit2、
SSH 接続のために paramiko のようなライブラリをわざわざ使うのは大がかりだったり、
rsync に相当するようなこなれたライブラリが存在しなかったりする場合があります。
そのような時は標準ライブラリの subprocess モジュールを利用し、Python から外部コマンドを呼び出すことになるでしょう。
しかしながら、Python のチュートリアルページには subprocess モジュールの解説はなく、
いきなり標準ライブラリのリファレンスを読むことになります。
subprocess モジュールはバージョンアップに従いAPIが多数追加されており、また各種OSの事情が同じ箇所に記載されているため、一見して利用法をなかなか掴みにくいです。
この記事では対象環境を Linux に絞り、シェルスクリプトと Python スクリプトを対比した上で subprocess モジュールの典型的な利用方法について述べます。
また、記事の後半では subprocess モジュールの詳細に立ち入り、込み入ったケースでの注意点について記載します。
対象読者
subprocessを雰囲気で利用している人- 具体的には公式のリファレンスや巷の解説記事を多少読んで
import subprocessしたことがある人
- 具体的には公式のリファレンスや巷の解説記事を多少読んで
対象環境
- Linux 環境の Python 3.8 以降を対象とします
- macOS 環境の場合も基本的な仕組みや利用方法は同じですが、細部の挙動が異なるかもしれません
- Windows 環境は仕組みが大きく異なるため説明を割愛させていただきます
- メインの動作確認環境は Linux の Python 3.11.5 (記事執筆時点での最新安定版)です
- 記事の後半では CPython 3.11.5 のソースコードを基に細かい挙動を確認しています
- python/cpython at v3.11.5 - GitHub
- 他の処理系では挙動が異なる可能性があります
- 将来のバージョンアップで挙動が変更される可能性もあります
- なお、Python には非同期処理向けの
asyncio.subprocessモジュールも存在しますが、この記事では解説しません
シェルスクリプトとPythonの比較
以下、シェルスクリプトのコード片には # sh 、Python スクリプトのコード片には # python と記載しています。
また、Python のコード片では以下のモジュールと定数を import しているものとします。
# python import subprocess from subprocess import PIPE import sys
コマンドを起動する(最も単純な使い方)
subprocess.run 関数にコマンドを文字列のリストとして渡すことで子プロセスを起動できます。
# sh ls -l
# python subprocess.run(["ls", "-l"])
終了ステータスを取得する
subprocess.run 関数の戻り値の returncode インスタンス変数で子プロセスの終了ステータスを取得できます。
# sh ls -l no_such_file echo $?
# python result = subprocess.run(["ls", "-l", "no_such_file"]) print(result.returncode)
標準出力を捕捉する
subprocess.run 関数の stdout 引数に subprocess.PIPE 定数を指定することで、
子プロセスの標準出力を捕捉して Python プログラムから扱うことができます。
出力は戻り値の stdout インスタンス変数にバイト列 (bytes) として格納されています。
# sh output="$(ls -l)" echo "$output"
# python result = subprocess.run(["ls", "-l"], stdout=PIPE) sys.stdout.buffer.write(result.stdout)
標準エラー出力も捕捉したい場合は capture_output=True を指定します。
これは、stdout=PIPE, stderr=PIPE の略記となっています。
# python result = subprocess.run(["ls", "-l"], capture_output=True) sys.stdout.buffer.write(result.stdout) sys.stderr.buffer.write(result.stderr) # もしくは result = subprocess.run(["ls", "-l"], stdout=PIPE, stderr=PIPE) sys.stdout.buffer.write(result.stdout) sys.stderr.buffer.write(result.stderr)
出力をバイト列 (bytes) ではなく文字列 (str) として捕捉したい場合、
text / encoding / errors のいずれかの引数を指定します。
基本的には encoding="utf-8" のようにエンコーディングを指定しておくとよいでしょう。
# python result = subprocess.run(["ls", "-l"], capture_output=True, encoding="utf-8") print(result.stdout, end="") print(result.stderr, end="")
標準入出力をリダイレクトする
subprocess.run 関数の stdout 引数にファイルオブジェクトを渡すことで、
子プロセスの標準出力をファイルにリダイレクトできます 1 。
この際、ファイルオブジェクトはバイナリモード ("b") で開く必要があります。
# sh ls -l >ls.txt
# python with open("ls.txt", "wb") as f: subprocess.run(["ls", "-l"], stdout=f)
追記 (>>) 相当の挙動にするには open 関数のモードを "a" とします。
# sh ls -l >>ls.txt
# python with open("ls.txt", "ab") as f: subprocess.run(["ls", "-l"], stdout=f)
子プロセスの標準入力や標準エラー出力をリダイレクトしたい場合も同様に書くことができます
(stdin 引数・ stderr 引数を使います)。
# sh grep foo <bar.txt ls -l no_such_file 2>ls.txt
# python with open("bar.txt", "rb") as f: subprocess.run(["grep", "foo"], stdin=f) with open("ls.txt", "wb") as f: subprocess.run(["ls", "-l", "no_such_file"], stderr=f)
標準エラー出力を標準出力にマージして捕捉する
stderr 引数に subprocess.STDOUT 定数を指定することで、子プロセスの標準エラー出力を標準出力にマージできます。
# sh output="$(ls -l no_such_file 2>&1)" echo "$output"
# python result = subprocess.run( ["ls", "-l", "no_such_file"], stdout=PIPE, stderr=subprocess.STDOUT, ) sys.stdout.buffer.write(result.stdout)
なお、subprocess.STDOUT はこのケースのための特別な定数であり、
逆に標準出力を標準エラー出力にマージするような操作(シェルスクリプトの >&2 に相当)は用意されていません。
出力を全て捨てる
子プロセスの標準出力・標準エラー出力を全て捨てる以下のイディオムは subprocess でも同様に書くことができます。
# sh grep foo bar.txt >/dev/null 2>&1 echo $?
# python result = subprocess.run( ["grep", "foo", "bar.txt"], stdout=subprocess.DEVNULL, stderr=subprocess.STDOUT, ) print(result.returncode)
終了ステータスが0でなければ例外を発生させる
check 引数に True を指定すると returncode が 0 でない場合に例外が発生するようになります。
# sh set -e ls -l no_such_file echo unreachable # ls がエラーの場合この行は実行されない
# python subprocess.run(["ls", "-l", "no_such_file"], check=True) print("unreachable") # ls がエラーの場合この行は実行されない
subprocess.CalledProcessError 例外を捕捉することで子プロセスの終了ステータスや標準出力を得ることができます。
# python try: result = subprocess.run( ["ls", "-l", "no_such_file"], capture_output=True, check=True, encoding="utf-8", ) print(result.returncode) print(result.stdout) print(result.stderr) except subprocess.CalledProcessError as e: print(e.returncode) print(e.stdout) print(e.stderr)
Pythonのバイト列・文字列をコマンドに渡す
Pythonで生成したバイト列をコマンドの入力に渡すには input 引数を利用します。
# sh echo hello | cat
# python p = subprocess.run(["cat"], input=b"hello\n")
encoding 引数を指定すれば文字列 (str) を渡すことも可能です。
# python p = subprocess.run(["cat"], input="hello\n", encoding="utf-8")
もちろん、stdout / stderr / capture_output 引数を利用すれば出力の捕捉もできます。
# sh output="$(echo hello world | cut -d ' ' -f 2)" echo "$output"
# python(バイト列版) result = subprocess.run( ["cut", "-d", " ", "-f", "2"], input=b"hello world\n", stdout=PIPE, ) sys.stdout.buffer.write(result.stdout) # python(文字列版) result = subprocess.run( ["cut", "-d", " ", "-f", "2"], input="hello world\n", stdout=PIPE, encoding="utf-8", ) print(result.stdout, end="")
並行処理を行う
subprocess.run 関数はコマンドが終了するまで待機するため、複数のコマンドを実行しようとすると直列実行となります。
例えば以下のスクリプトを実行すると全体で 3 秒ほどの時間がかかります。
# sh sleep 1 sleep 1 sleep 1
# python subprocess.run(["sleep", "1"]) subprocess.run(["sleep", "1"]) subprocess.run(["sleep", "1"])
並行処理を行うには subprocess.Popen コンストラクタを利用して処理を開始し、
作成された Popen オブジェクトの communicate メソッドで終了を待つように書き換えます。
以下の例では 1 秒ほどで全体の処理が完了します。
# sh sleep 1 & sleep 1 & sleep 1 & wait
# python ps = [] ps.append(subprocess.Popen(["sleep", "1"])) ps.append(subprocess.Popen(["sleep", "1"])) ps.append(subprocess.Popen(["sleep", "1"])) for p in ps: p.communicate()
Popen と communicate で標準入出力を扱う
これまで利用してきた subprocess.run 関数は subprocess.Popen コンストラクタと
Popen.communicate メソッドを組み合わせて利用しやすい形にしたものです。
直接 Popen と communicate を使って標準入出力を扱う場合は以下のように書けます。
# sh output="$(echo hello world | cut -d ' ' -f 2)" echo "$output"
# python(バイト列版) process = subprocess.Popen( ["cut", "-d", " ", "-f", "2"], stdin=PIPE, stdout=PIPE, ) stdout, _stderr = process.communicate(input=b"hello world\n") sys.stdout.buffer.write(result.stdout) # python(文字列版) process = subprocess.Popen( ["cut", "-d", " ", "-f", "2"], stdin=PIPE, stdout=PIPE, encoding="utf-8" ) stdout, _stderr = process.communicate(input="hello world\n") print(stdout, end="")
stdin/stdout/stderrとtext/encoding/errors引数はPopenコンストラクタに与えますinput引数はcommunicateメソッドに与えますinput引数で入力を与える場合、stdin引数に明示的にPIPEを与える必要がありますsubprocess.runの場合はinputを指定すると暗黙的に与えられていました
capture_output引数はsubprocess.runにのみ存在し、Popenコンストラクタにはありませんcapture_output=True相当の処理を行う場合はstdout=PIPE, stderr=PIPEを両方指定する必要があります
パイプ処理を行う
Popen オブジェクトを複数用い、入力を受け取りたいコマンド側の stdin 引数に出力コマンド側の stdout インスタンス変数を渡すことでシェルスクリプトのパイプを再現できます。
# sh output="$(yes | head)" echo "$output"
# python p1 = subprocess.Popen(["yes"], stdout=PIPE) p2 = subprocess.Popen(["head"], stdin=p1.stdout, stdout=PIPE) p1.stdout.close() stdout, _stderr = p2.communicate() sys.stdout.buffer.write(stdout)
なお、別の Popen の stdin として渡した stdout については close() を呼び出すべきです。
上記の例では head コマンドの終了後に即座に yes コマンドも終了させるために必要になります(詳細は後述します)。
3つ以上のコマンドを繋ぐ場合も同様です。
# sh output="$(seq 1 100000 | grep 3 | tail)" echo "$output"
# python p1 = subprocess.Popen(["seq", "1", "100000"], stdout=PIPE) p2 = subprocess.Popen(["grep", "3"], stdin=p1.stdout, stdout=PIPE) p1.stdout.close() p3 = subprocess.Popen(["tail"], stdin=p2.stdout, stdout=PIPE) p2.stdout.close() stdout, _stderr = p3.communicate() sys.stdout.buffer.write(stdout)
タイムアウトを設定する
subprocess.run 関数に timeout 引数を渡すことでタイムアウトの秒数を設定できます。
# sh (GNU coreutils の timeout コマンドを利用) timeout 1 sleep 3
# python subprocess.run(["sleep", "3"], timeout=1)
Popen コンストラクタを利用する場合は communicate メソッドに timeout 引数を渡すことでタイムアウトさせることができます。
# python try: p = subprocess.Popen(["sleep", "3"]) p.communicate(timeout=1) except subprocess.TimeoutExpired: p.kill()
シェル経由でコマンドを起動する(要注意)
shell 引数に True を渡すことで文字列を sh のコマンドとして実行できます。
# sh sh -c 'ls -l ~/.*'
# python subprocess.run("ls -l ~/.*", shell=True)
ただし shell=True はOSコマンドインジェクション脆弱性に繋がりやすいため基本的には利用は避けた方がよいでしょう。
シェル特有の挙動を Python 上で再現したい場合は以下のモジュールや関数で代替できます。
- ワイルドカード文字列 (
*,?,[...]) の利用 - パスに含まれるユーザのホームディレクトリ (
~) の展開os.path.expanduser関数を利用する
- 環境変数 (
${...}) の展開os.path.expandvars関数を利用する
subprocessの詳細仕様と内部実装
この節では subprocess モジュールのより詳しい仕様や、Linux 環境の CPython 処理系の実際の挙動について見ていきます。
プロセス間通信の流れ(概要)
これまでシェルスクリプトと Python の subprocess モジュールを対比して説明してきましたが、実際のところ裏側の仕組みもほぼ同じです。
「標準出力を捕捉する」節の以下の例を考えます。
# sh output="$(ls -l)"
# python result = subprocess.run(["ls", "-l"], stdout=PIPE)
シェル・Pythonとも、Linuxの以下の仕組みを用いて子プロセスの起動と標準出力の捕捉を実現しています。
- パイプ: プロセス間通信を行うための仕組みで、書き込み側・読み出し側の 2 種類の端点が存在する。あるプロセスが書き込み側に出力した内容を別のプロセスが読み出し側から入力として扱える
- ファイルディスクリプタ: ファイル・端末・パイプに対する操作のために付与された番号。0, 1, 2 番はそれぞれ標準入力・標準出力・標準エラー出力として扱われる
- fork: プロセスを複製して子プロセスを作成するための仕組み
- exec: プロセスを新たに起動したプログラムのプロセスで置き換えるための仕組み
Python で subprocess.run を実行した処理の流れは以下の通りです。
- (初期状態)親プロセス(
python3)のファイルディスクリプタ 0, 1, 2 番に標準入力・標準出力・標準エラー出力となる端末やファイルが割り当てられている - パイプを作成する。この際読み出し側と書き込み側の 2 つの端点が作成され、それぞれに新規のファイルディスクリプタが割り当てられる
- プロセスを複製し、子プロセスを作る (fork)
- 子プロセスの標準出力(ファイルディスクリプタ 1 番)を 2. で作成したパイプの書き込み側に置き換える
- 子プロセスを別のプログラム(例:
ls)に置き換える (exec) 。ファイルディスクリプタは 0, 1, 2 番のみ引き継がれる - 不要なファイルディスクリプタを閉じる
- 子プロセス (
ls) は標準出力(=パイプの書き込み側)に結果を書き込む - 親プロセス (
python3) はパイプの読み出し側から 7. の結果(lsの出力)を読み出す
この流れを図示すると以下のようになります。 3 番以降のファイルディスクリプタ番号は一例であり、実際にこの番号が割り当てられるとは限りません。

以下、この処理を更に詳しく見ていきます。
プロセス間通信の実装(詳細)
以下のように標準入力・標準出力・標準エラー出力全てに PIPE を指定してプロセスを作成した場合、
CPython 処理系内部ではどのような処理が行われているのでしょうか?
p = subprocess.Popen(["ls", "-l"], stdin=PIPE, stdout=PIPE, stderr=PIPE)
結論として、fork → exec 後の最終的な状態を図示すると以下のようになります。

具体的な処理は以下の通りです。 これは CPython のソースコードの subprocess モジュールの実装と POSIX 環境向けのC言語実装に対応します。
os.pipe2関数を用いて4種類のパイプ(8個のファイルディスクリプタ)を新たに作成する- 親プロセスが
stdin変数経由で書き込み、子プロセスが標準入力として読み出すためのパイプ (p2cread,p2cwrite) - 子プロセスが標準出力として書き込み、親プロセスが
stdout変数経由で書き込むためのパイプ (c2pread,c2pwrite) - 子プロセスが標準エラー出力として書き込み、親プロセスが
stderr変数経由で書き込むためのパイプ (errread,errwrite) - 正常に子のプログラムを起動できなかった際にエラーを通知するためのパイプ (
errpipe_read,errpipe_write)
- 親プロセスが
- 上記のファイルディスクリプタのうち、親プロセスが利用するものをファイルオブジェクトとしてラップし、
Popenオブジェクトのインスタンス変数として設定する- 標準入力への書き込み側 (
p2cwrite) をstdinインスタンス変数に設定する - 標準出力の読み出し側 (
c2pread) をstdoutインスタンス変数に設定する - 標準エラー出力の読み出し側 (
errread) をstderrインスタンス変数に設定する
- 標準入力への書き込み側 (
- プロセスの複製 (fork) 2 を行い、子プロセスを作成する
- fork 後、パイプのファイルディスクリプタのうち自プロセスが利用しない方を閉じる(
close) - また、子プロセスはファイルディスクリプタの複製 (
dup2) によってp2cread,c2pwrite,errwriteをそれぞれファイルディスクリプタ 0, 1, 2 (=標準入力・標準出力・標準エラー出力)として扱えるようにする
- fork 後、パイプのファイルディスクリプタのうち自プロセスが利用しない方を閉じる(
- 指定されたプログラムで子プロセスを置き換える (exec) 3
- exec 時に子プロセスのほとんどのファイルディスクリプタは閉じられる 4
- ファイルディスクリプタ 0, 1, 2 (=標準入力・標準出力・標準エラー出力)は子プロセスに継承され、これを介して親プロセスと子プロセスが通信する
- exec に失敗した場合はその旨を
errpipe_write→errpipe_read経由で親プロセスに通知する。通知されたエラーは Python の例外として送出される - 親プロセスの
errpipe_readは exec が正常に行われた段階で不要となるため閉じられる
子プロセス同士をパイプする際に close が必要な理由
公式リファレンスの「シェルのパイプラインを置き換える」の節では以下のようなコードが例示されています(後の説明のため呼び出すコマンドを改変しています)。
p1 = Popen(["yes"], stdout=PIPE) p2 = Popen(["head"], stdin=p1.stdout, stdout=PIPE) p1.stdout.close() # Allow p1 to receive a SIGPIPE if p2 exits. output = p2.communicate()[0]
ここで、p1.stdout.close() を行う理由として "Allow p1 to receive a SIGPIPE if p2 exits." (p2 が終了した場合に p1 が SIGPIPE を受け取れるようにする)と書かれています。
これはどういう意味なのでしょうか?
上記のスクリプトにおける親プロセス (python3)・子プロセス (yes, head) とパイプの関係を図示すると以下のようになります。
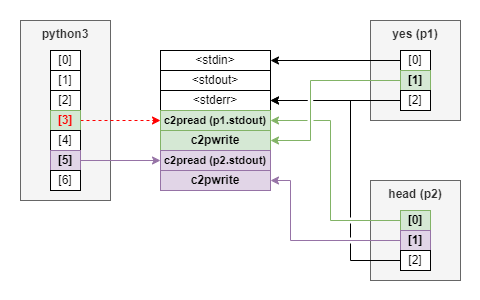
正しく p1.stdout.close() を呼び出した場合、head が終了すると yes の標準出力に対応するパイプの読み出し側が 1 つも存在しなくなります。
ここで yes が標準出力に書き込もうとすると、パイプが破壊されたことを表すシグナルである SIGPIPE が yes に対して送られます。
SIGPIPE を受け取ったプロセスのデフォルトの挙動として yes は終了し、これにより「head 終了後即座に yes も終了する」という挙動が実現されます。
一方で p1.stdout.close() を呼び出さなかった場合は、head が終了しても yes の標準出力に対応するパイプの読み出し側を親プロセス側がまだ保持しています。
SIGPIPE は「パイプの全ての読み出し側が close した状態で書き込み側が write した」際に発生するシグナルであるため、
この状態で SIGPIPE が yes に送られることはありません。
よって、yes は head が終了した後も動き続けることになります(p1 オブジェクトが破棄されるタイミングで yes は終了します)。
以上より、「p2 が終了した場合に p1 が SIGPIPE を受け取れるようにする」には p1.stdout.close() を呼ぶ必要がある、ということになります。
いずれにせよ、「ファイルオブジェクト(ファイルディスクリプタ)は不要になった時点で閉じる」という原則通りに考えておけばよいでしょう。
Pythonとパイプ書き込みエラー
Python 処理系自身は起動時に SIGPIPE シグナルを無視するよう設定されており、破損したパイプに書き込んでも処理系が強制終了することはありません。
その代わり、書き込みに失敗した場合 5 に送出される BrokenPipeError 例外を適切にハンドリングする必要があります。
なお、Popen.communicate および subprocess.run は BrokenPipeError を捕捉した上で無視するようになっていますが、
直接 stdin.write を使うと BrokenPipeError が送出されます。
# BrokenPipeError は送出されない p = subprocess.Popen(["head"], stdin=PIPE) p.communicate(input=b"\n" * 100000) # BrokenPipeError が送出される場合がある p = subprocess.Popen(["head"], stdin=PIPE) p.stdin.write(b"\n" * 100000) p.wait()
デッドロックと communicate
公式リファレンスの Popen.stdin / Popen.stdout / Popen.stderr には以下のような警告があります。
警告:
.stdin.write,.stdout.read,.stderr.readを利用すると、別のパイプの OS パイプバッファーがいっぱいになってデッドロックが発生する恐れがあります。これを避けるためにはcommunicate()を利用してください。
例えば .stdin.write, .stdout.read を同時に使う場合、以下のいずれかの状況に陥ることがあります。
- 標準入力を与えなければパイプライン処理が進まず標準出力に結果が出力されない
- =
.stdin.write(...)しなければ.stdout.read(...)がブロックする
- =
- 標準出力を読まなければパイプが一杯で標準入力を与えられない
- =
.stdout.read(...)しなければ.stdin.write(...)がブロックする
- =
単純な実装では現在どちらの状況であるかを判定できないまま .stdin.write(...), .stdout.read(...) を呼ぶことになり、それがブロックすることでデッドロックしてしまいます。
きちんと対応しようとするとselectors モジュールを用いたI/O多重化を行うことになります 6 。
通常の処理の場合は単に communicate() を利用するのが得策でしょう。
ただし communicate() の入出力データはメモリ上に載るため、非常に大きなデータを扱う場合は注意が必要です。これも公式リファレンスに注釈があります。
注釈: 受信したデータはメモリにバッファーされます。そのため、返されるデータが大きいかあるいは制限がないような場合はこのメソッドを使うべきではありません。
大量のデータを扱う用途ではインメモリ処理を行うのではなく、一度ファイルを経由して入出力する等の工夫が必要でしょう。
おわりに
今回は Python の subprocess モジュールについて解説しました。
このモジュールは典型的な使い方で雑に使う分にはそれなりに容易に使えるのですが、
込み入ったケースでは裏側の仕組みを知っていないと自信を持って使えない感じはあります。
この記事が subprocess モジュールを利用する上で何か助けになれば幸いです。
なお、他のプログラミング言語の外部コマンド起動用モジュール(Ruby の IO, Go の os/exec, Rust の std::process, etc...)
も基本的には似た実装であるため、一度仕組みを理解しておけば Python 以外の言語を使う際にも役立つはずです。
皆さんもお好みの言語の I/O 系のモジュールの設計や実装について調べてみると面白いかもしれません。
採用情報
朝日ネットでは新卒採用・キャリア採用を行っております。


-
このファイルオブジェクトからは
fileno()メソッドで有効なファイルディスクリプタを取得できる必要があります。つまりファイルディスクリプタを持たないio.BytesIO等を渡すことはできません。↩ -
libc の関数上は
vfork/fork/posix_spawnのいずれかが呼ばれます(大抵の場合はvforkです)。実際に使用されるシステムコールについては libc 実装によるため、straceコマンド等で挙動を確認したい場合はよく確認しましょう(例えばclone3システムコールが呼ばれる場合があります)。↩ -
libc の関数上は
execv/execveのいずれかが呼ばれます(Popenコンストラクタでenv引数を指定した場合は後者)。↩ -
Popenコンストラクタのclose_fds引数がデフォルトでTrueであることによります。また、一般に Python 上で作成されたファイルディスクリプタは継承不可 (FD_CLOEXEC) の設定となっているため、仮にclose_fd=Falseの場合であっても exec と同時にほぼ全てのファイルディスクリプタが閉じられます。↩ -
具体的には libc の
write関数の戻り値がエラー値で、errnoとしてEPIPEが設定された場合です。↩ -
communicate()メソッドの内部実装 でもこのモジュールが利用されています。なお、標準入力・標準出力・標準エラー出力のいずれか1つしかパイプを利用しない場合であれば安全にread/writeを使うことができ、communicate()もそのような実装になっています。↩