
はじめに
開発部の ikasat です。 Python の言語・ライブラリ・処理系はプログラマのタスクを手早く簡単にこなせるようにするために設計されており、数行程度のコードを書いただけでも内部で様々なことをやってくれます。 しかし、この便利さが特定のユースケースにおいては逆にお節介になってしまうこともあり、また内部動作が複雑であることにより挙動を修正する方法も分からなくなりがちです。
特に組み込みの open 関数や標準入出力 (sys.stdin, sys.stdout) はその最たる例であり、UnicodeEncodeError / UnicodeDecodeError や TypeError: a bytes-like object is required は Python を使った人であれば誰もが見たことのあるエラーメッセージでしょう。
私自身これまでこの類のエラーが出た時には検索して出てきた情報を基に場当たり的な対処をしてきましたが、この機会に入出力の仕組みと io モジュールについて調べることでようやく問題に確実に対処できるようになりました。
というわけで今回は Python の入出力についてやや深めに解説していきます。
対象読者
openやsys.stdoutを雰囲気で利用している人- 具体的には Python チュートリアル くらいの内容は理解しているが io モジュールのリファレンス は読んでいない・読んだがよくわからなかった人
本記事の構成
- 最初に I/O に関するよくある問題への対処方法について記載します
- 次にこの対処方法に関連した
ioモジュールの解説を行います - おまけとして CPython の内部実装に触れたり他言語 (Java, Go) の I/O 系モジュールの比較を行ったりします
対象環境
- Windows, macOS, Linux の Python 3.6 以降を対象とします
- メインの動作確認環境は Linux の Python 3.9.5 です
- 細かい挙動については CPython 3.9.5 のソースコードを確認しています
- python/cpython at v3.9.5 - GitHub
- 他の処理系では挙動が異なる可能性があります
よくある問題への対処
この節では Python の入出力周りで発生しがちな問題の解決策について提示します。
open の encoding 引数を指定しよう
open 関数でテキストファイルを読み書きする際にはとにかく encoding 引数を指定しましょう。 基本的にこれが UnicodeEncodeError / UnicodeDecodeError に対する最も有効な解決策となります。
with open("foo.txt", encoding="utf-8") as f: obj = json.load(f)
encoding を指定しなかった場合はデフォルトで locale.getpreferredencoding() で取得可能なエンコーディングが利用されますが、これにより予期しない事態が発生する場合があります。
特に Windows の日本語ロケールではほぼ強制的に "cp932" (Shift_JIS の拡張)となるため UnicodeDecodeError / UnicodeEncodeError が発生しやすくなります。
一括してファイル入出力のエンコーディングを変更するには?
自分ですぐに修正できるソースコードなら先ほどのように一つ一つ encoding 引数を指定すれば解決するのですが、例えば pip install で外部パッケージをインストールしている最中にエラーになった場合などはこの方法は使えません。
よって、以下の一括してファイル入出力のエンコーディングを変更する方法を利用することになります。
- Python 3.7 以降であり読んでいるファイルが UTF-8 であれば UTF-8 モードを使う
PYTHONUTF8=1環境変数を利用する- 現代において
pipで導入するようなパッケージが読み書きするファイルは UTF-8 が前提のはずなので大抵はこれで事足りる
- Linux の場合ロケール系の環境変数を指定する
- 例えば UTF-8 の場合
LANGやLC_ALLにja_JP.UTF-8,en_US.UTF-8,C.UTF-8等を指定する
- 例えば UTF-8 の場合
- usercustomize 等を使い
open関数を差し替えて強制的にencoding引数を変更する- かなり無理矢理だがどの環境・バージョン・エンコーディングでも利用できる(詳細な手順については割愛)
Python 3.7 以降は PYTHONUTF8 環境変数に空でない文字列を指定する、もしくは処理系の起動時コマンドライン引数として -Xutf8 を与えることで UTF-8 モードになります。
環境変数を(一時的に)設定して起動する例について以下に示します。
PYTHONUTF8=1 python3 foo.py
Windows の場合は以下のように起動します。
set PYTHONUTF8=1
py foo.py
str / bytes の変換に使う encoding について
open 関数の encoding 引数とは異なり、str の encode メソッドや bytes の decode メソッドの encoding 引数を指定しない場合のデフォルト値は "utf-8" です。
実際には sys.getdefaultencoding() の結果が使われますがこれは Python 3 では常に "utf-8" です。
>>> 'あ'.encode() b'\xe3\x81\x82' >>> b'\xe3\x81\x82'.decode() 'あ' >>> sys.getdefaultencoding() 'utf-8'
これとは別に組み込みの str / bytes 関数を使って文字列とバイト列を変換する方法もありますが、こちらの場合はきちんと encoding 引数を指定しないとエラーが発生したり意図しない文字列が返ってきたりすることに注意しましょう。そのため str / bytes の変換目的では上記の encode / decode メソッドを一貫して用いた方がよいと思われます。
>>> bytes('あ', encoding='utf-8') b'\xe3\x81\x82' >>> str(b'\xe3\x81\x82', encoding='utf-8') 'あ' >>> bytes('あ') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: string argument without an encoding >>> str(b'\xe3\x81\x82') "b'\\xe3\\x81\\x82'"
標準入出力のエンコーディングを変えるには?
まず本当に標準入出力のエンコーディングを変更すべきか、変更して問題が解決するのかをあらかじめよく考えましょう。 その上で標準入出力のエンコーディングを強制的に変更するには以下の方法が利用できます。
Windows 以外の場合 PYTHONIOENCODING を書き換えることで標準入出力の encoding を指定できます。
PYTHONIOENCODING=cp932 python3 foo.py
Windows の場合コンソール入出力に常に Unicode 系の文字コードを利用する(正確に言うとワイド文字 API を利用する)ためこの変数の指定は意味を持ちません。
これを回避するには PYTHONLEGACYWINDOWSSTDIO 環境変数を指定します。
set PYTHONIOENCODING=cp932
set PYTHONLEGACYWINDOWSSTDIO=1
py foo.py
Python 3.7 以降であれば reconfigure メソッドを呼ぶことでもエンコーディング等の設定を変更できます。
この際 stdin についてはまだ 1 バイトも入力を消費していない必要があります。
sys.stdin.reconfigure(encoding="cp932") sys.stdout.reconfigure(encoding="cp932") sys.stderr.reconfigure(encoding="cp932")
Python 3.6 以前であれば sys.stdin / sys.stdout / sys.stderr 自体を以下のように置き換えることで個別に設定できます(詳細は後述しますが line_buffering の指定は元の挙動に寄せています)。
sys.stdin = io.TextIOWrapper(
sys.stdin.buffer,
encoding="cp932",
line_buffering=sys.stdin.isatty(),
)
sys.stdout = io.TextIOWrapper(
sys.stdout.buffer,
encoding="cp932",
line_buffering=sys.stdout.isatty(),
)
sys.stderr = io.TextIOWrapper(
sys.stderr.buffer,
encoding="cp932",
line_buffering=True,
)
codecs.open ではなく組み込みの open を使おう
codecs モジュールの open ではなく組み込みの open を使いましょう。
Python 3 系では組み込みの open 関数は io モジュールの open と同義なのですが、
Python 2.0 からある codecs モジュールと比べて 2.6 で導入された io モジュールの方が新しい設計となっています。
Web 検索では Python 2 時代の文書がまだ多くヒットするため codecs.open もよく見かけるのですが、あるファイルをテキストとして読み書きする通常のケースでは組み込みの open 関数で十分です。
# Before with codecs.open("foo.txt", encoding="cp932") as f: pass # After with open("foo.txt", encoding="cp932") as f: pass
codecs の StreamReader や StreamWriter を利用してストリーム処理を行うケースの代わりとしては io.TextIOWrapper が利用できます。
# Before text_in = codecs.getreader("cp932")(binary_in) text_out = codecs.getwriter("cp932")(binary_out) # After text_in = io.TextIOWrapper(binary_in, encoding="cp932") text_out = io.TextIOWrapper(binary_out, encoding="cp932", write_through=True)
なお StreamReader / StreamWriter の問題点については以下の PEP に記載されています(PEP 自体の Status は Deferred ですが……)。
ファイルへの書き込みを正しく行おう
ファイルオブジェクトの書き込みについては以下の条件を満たすまで実際にはファイルへの書き込みは行われません。
- 明示的に
flush()メソッドを呼んだ場合 - ファイルオブジェクト内部のバッファが埋まった場合
- (テキストモードかつラインバッファリングが有効な場合)改行文字が存在した場合
close()メソッドが呼ばれた場合__del__,__exit__メソッドが呼ばれた場合も同様
flush() や close() の呼び忘れが起こると書き込みが中途半端になるなどの意図しない結果を招く場合があります。
できる限り with ブロックでファイルオブジェクトの生存期間を明示するようにしておくとこのような問題は起こりません。
この場合は with ブロックの終わりに __exit__ メソッドが呼ばれることによって書き込みが行われます。
# Before f = open("foo.txt", encoding="utf-8") ... f.close() # After with open("foo.txt", encoding="utf-8") as f: ...
Python の I/O を知る
この節では Python の open 関数の詳しい挙動とそれを支える io モジュールのクラスについて解説します。
Python における str と bytes の変換
Python の I/O を理解するにあたって、そもそも Python 3 の str とは何か、ということを知っておく必要があります。
まず Python において「文字」は「Unicode コードポイント(符号位置)」で表されます。
例えば文字 あ には Unicode において 12354 (16進数で 0x3042)というコードポイントが割り当てられています。文字のコードポイントは組み込みの ord 関数で調べることができます。
>>> ord("あ") 12354 >>> ord("い") 12356 >>> ord("う") 12358
そして str は「Unicode コードポイントの列」です。
簡単に言うと文字列 "あいう" は内部的には [12354, 12356, 12358] のような数値の列として扱われていると考えてください(正確には Python のリストを使っているわけではありませんし、利用される文字種によってより効率の良い内部表現が使われています)。
一方で Python の外部から入力されてくるもの・外部に出力するものは全て bytes となっており、これはエンコーディングもそもそもテキストかどうかも不明な単なるバイト列(バイナリ)です。
この入出力を str (テキスト)として扱うには必ずエンコーディングを与えて Unicode のコードポイントに変換してあげる必要があります。例えば bytes の decode メソッドや str の encode メソッドは以下のような意味合いを持ちます。
bytesのdecode(encoding=...)メソッド- 単なるバイト列 (
bytes) を指定されたencodingの文字列であると解釈(デコード)し、 Unicode のコードポイント列 (str) に変換する
- 単なるバイト列 (
strのencode(encoding=...)メソッド- Unicode のコードポイント列 (
str) を指定された文字コードの文字列に変換(エンコード)し、それを単なるバイト列 (bytes) として扱う
- Unicode のコードポイント列 (
なお、ここでわざわざこのような説明をしたのはプログラミング言語によっては外部入出力をそのまま文字列のように扱う場合があるためです(Python 2 時代の str もそうでした)。
とにかく Python 3 の外部入出力をテキストとして扱うには Unicode コードポイントとの相互変換が必要であり、これは後述の「raw I/O・バイナリ I/O」と「テキスト I/O」の区別に関わってきます。
io モジュールについて知る
Python で外部入出力を扱う代表的な関数といえば open です。この関数は指定する mode などの引数によって性質の大きく異なったオブジェクトを返します。
この挙動について把握するにはまず io モジュールで定義されているクラスについて知っておく必要があります。
Python の入出力に関するオブジェクトは以下の 3 種類に大別されます(io モジュールのリファレンスに書いてあることの要約です)。
- raw I/O
- OS に近い部分とやり取りする生の入出力(別名: unbuffered I/O)
- raw I/O の具象クラスは
RawIOBase抽象基底クラスを継承・実装する read()メソッドの戻り値、write(b)メソッドの引数はbytes- 例:
FileIOopen関数でバイナリモードかつbufferingに0を指定するとこれが返ってくる
- バイナリ I/O
- バッファを持つ入出力(別名: buffered I/O)
- バイナリ I/O の具象クラスは
BufferedIOBase抽象基底クラスを継承・実装する read()メソッドの戻り値、write(b)メソッドの引数はbytes- 基本的に raw I/O のオブジェクトを内包している
- 例:
BufferedReaderIO,BufferedWriterIO,BufferedRandomIOopen関数でバイナリモードかつbufferingに0以外を指定するとこれが返ってくる
- インメモリのバイナリ I/O として
BytesIOが存在する
- テキスト I/O
- テキストとバイナリの変換機構を持つ入出力
- テキスト I/O の
TextIOBase抽象基底クラスを継承・実装する read()メソッドの戻り値、write(s)メソッドの引数はstr- 基本的にバイナリ I/O(まれに raw I/O)のオブジェクトを内包している
- 例:
TextIOWrapperopen関数でテキストモードを指定するとこれが返ってくる
- インメモリのテキスト I/O として
StringIOが存在する
io モジュールの各種クラスを図示すると以下のようになります。

open 関数の引数
組み込みの open 関数は以下のようなシグネチャを持ちます。以下、この引数の意味とそれを指定した際の挙動について説明していきます。
open( file, mode='r', buffering=-1, # モードとバッファリング encoding=None, errors=None, newline=None, # テキスト I/O に関する設定 closefd=True, opener=None, # raw I/O に関する設定 )
モードとバッファリング
open 関数の mode として指定できる文字は(非推奨のものを除くと)現在 7 種類あります。
これは「raw IO に関する指定」「バイナリ/テキストに関する指定」の 2 種類に分けられます。
「raw IO (FileIO) に関する指定」は以下の 5 つです。このうち + を除く r, w, a, x については必ずどれか 1 つだけを指定する必要があります。
| 文字 | 意味 |
|---|---|
r |
読み込み用。ファイルが存在しなければエラーとする。 |
w |
書き込み用。ファイルが存在しなければ作成する。ファイルが既に存在すれば内容を 0 バイトに切り詰める。 |
a |
書き込み用。ファイルが存在しなければ作成する。ファイルが既に存在すれば書き込みは末尾への追記とする。 |
x |
書き込み用。ファイルが存在しなければ作成する。ファイルが既に存在すればエラーとする。 |
+ |
読み込み・書き込みの両方を可能にする。 |
「バイナリ/テキストに関する指定」は以下の 2 つです。何も指定しないと t となります。
| 文字 | 意味 |
|---|---|
b |
バイナリとして読み込む(バイナリ I/O もしくは raw I/O を返す) |
t |
テキストとして読み込む(テキスト I/O を返す) |
open 関数の返すファイルオブジェクトのクラスは mode と buffering の値によって以下のような流れで決まります。
なおテキストモードかつ buffering を 0 とすることはできません。
file(ファイルパス)とmode(r,w,a,x,+) を用いて raw I/O (FileIO) を開くbufferingの値によってバイナリ I/O を利用するかどうかを決める- 0 の場合 raw I/O をそのまま使う
- 0 でない場合 raw I/O をバイナリ I/O でラップする
- バイナリ I/O の種類は
modeの値によって分岐する:+を含む場合 →BufferedRandomrを含む場合 →BufferedReaderw,a,xを含む場合 →BufferedWriter
- バイナリ I/O の種類は
modeの値によってテキスト I/O を利用するかどうかを決めるbを含む場合 raw I/O・バイナリ I/O をそのまま使うbを含まない(tを含む)場合 raw I/O・バイナリ I/O をテキスト I/O (TextIOWrapper) でラップする
テキスト I/O に関する設定
encoding, errors, newline は TextIOWrapper の挙動を決める引数です。
encoding: 文字列のエンコーディング- デフォルトでは
locale.getpreferredencoding()の値が利用される codecsモジュールのリスト に存在するテキスト-バイナリ変換を利用できる
- デフォルトでは
errors: 文字列をデコードできなかった場合の処理モード- デフォルトは
"strict"(変換できない文字が出現した場合エラーとする) "ignore"はエラーを無視する"replace","xmlcharrefreplace","backslashreplace","namereplace"は変換できない文字を指定の方法で置き換える"surrogateescape"は変換できない文字を壊さずに保持でき、encode(errors="surrogateescape")することで元のバイト列に戻せるという性質がある
- デフォルトは
newline: 改行コードに関する処理モード- デフォルト (
None) では universal newlines モードが有効になり、入出力に含まれる改行を"\n"と相互に自動変換する- この場合、例えば Windows では入力に含まれる
"\r\n"(CR+LF) は Python 側で"\n"(LF) に変換され、出力する際は"\n"は"\r\n"に変換される
- この場合、例えば Windows では入力に含まれる
""を指定した場合は入力の"\r\n","\n","\r"を行末として扱うが"\n"に自動変換はせず、出力時に"\n"を自動変換することもない"\n","\r","\r\n"のいずれかを指定した場合は入力時に指定の文字列のみを行末として扱い、出力時に"\n"を指定の文字に自動変換する
- デフォルト (
raw I/O に関する設定
closefd, opener は raw I/O の作成と後処理に関する引数です。一般的な用途ではあまり使うことはないと思われます。
closefd: ファイルディスクリプタを閉じるか否か- デフォルトは
True(閉じる) sys.stdin,sys.stdout,sys.stderrではFalseとなっており、close()メソッドを呼び出した際にファイルディスクリプタ (0, 1, 2) が閉じないようになっている
- デフォルトは
opener: ファイルディスクリプタを開く関数- デフォルトは
Noneで、os.openを渡すのと同様の挙動(この関数は open 系システムコールのラッパーと考えてよい)
- デフォルトは
sys.stdin / sys.stdout / sys.stderr の正体
sys.stdin, sys.stdout, sys.stderr は大まかには以下のように初期化されます(CPython 実装ではこの初期化は Python ではなく C 言語で書かれています。pylifecycle.c の create_stdio 関数 が該当箇所です)。
sys.stdin = io.TextIOWrapper(
io.BufferedReader(
io.FileIO(0, "r", closefd=False),
),
line_buffering=os.isatty(0),
)
sys.stdout = io.TextIOWrapper(
io.BufferedWriter(
io.FileIO(1, "w", closefd=False),
),
line_buffering=os.isatty(1),
)
sys.stderr = io.TextIOWrapper(
io.BufferedWriter(
io.FileIO(2, "w", closefd=False),
),
line_buffering=True,
)
アプリケーションと OS とのやり取りの中ではファイルはファイルディスクリプタという識別子(番号)を用いて管理されており、ファイルディスクリプタ 0, 1, 2 はそれぞれ標準入力・標準出力・標準エラー出力に割り当てられています。
このファイルディスクリプタを FileIO の引数として与えることで Python のファイルオブジェクト (raw I/O) として扱うことができます。標準入力・標準出力が端末である場合(ファイル等にリダイレクトされていない場合)は TextIOWrapper の line_buffering が True となります(標準エラー出力では常に True です)。
なお、Windows の Python 3.6 以降では FileIO の代わりに専用のコンソール用の実装が利用されます。この挙動を無効化するのが PYTHONLEGACYWINDOWSSTDIO 環境変数です。
PYTHONUNBUFFERED 環境変数が空でない場合、もしくは処理系のコマンドラインオプションで -u を指定した場合は以下のように出力にバッファを使わなくなります(入力は引き続きバッファされます)。
sys.stdin = io.TextIOWrapper(
io.BufferedReader(
io.FileIO(0, "r", closefd=False),
),
)
sys.stdout = io.TextIOWrapper(
io.FileIO(1, "w", closefd=False),
write_through=True,
)
sys.stderr = io.TextIOWrapper(
io.FileIO(2, "w", closefd=False),
write_through=True,
)
ファイルオブジェクトの内容のコピー
shutil.copyfileobj でファイルオブジェクトの内容をコピーできます。
コピー元・コピー先には BytesIO や StringIO 等も使えます(shutil モジュールにあるのがかなりミスリーディングですが……)。
>>> src = io.StringIO("あいう") >>> dest_bin = io.BytesIO() >>> dest = io.TextIOWrapper(dest_bin, encoding="utf-8") >>> shutil.copyfileobj(src, dest) >>> dest.flush() >>> dest_bin.getvalue() b'\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86'
標準ライブラリでのファイルオブジェクトの使われ方
標準ライブラリの以下の関数・メソッドはファイルオブジェクトを返します。
urllib.request.urlopen(url)関数- ソケットオブジェクト の
makefile()メソッド gzip.open(filename),bz2.open(filename)関数zipfile.ZipFileオブジェクトのopen(name)メソッドtarfile.TarFileオブジェクトのextractfile(member)メソッド
以下の関数・メソッドはファイルオブジェクトを引数に取ります。
json.load(fp)/json.dump(obj, fp)関数json.load(fp)はjson.loads(fp.read())と同義(全バイトをメモリ上に一度に読み込む)json.load(fp)は内容が UTF-8, UTF-16, UTF-32 のいずれかであればバイナリ I/O も受け付ける(Python 3.6 以降)。一方json.dump(obj, fp)はテキスト I/O しか受け付けない
csv.reader(csvfile)/csv.writer(csvfile)関数csv.reader(csvfile)関数は文字列のイテレータ、csv.writer(csvfile)関数はwriteメソッドを持つオブジェクトを引数に取る- なお内包するファイルオブジェクトの Universal newline モードについては
newline=""(改行コードの自動変換を行わない)としておくことが推奨されている
urllib.request.urlopen(url)関数(data引数)tarfile.open関数(fileobj引数)、TarFile.addfileメソッド(fileobj引数)
このように標準ライブラリにはファイルオブジェクトを利用するメソッドが多くあります。 自分で実装するメソッドについてもファイルオブジェクトを受け取る・返すようにしておくとこれらのメソッドを簡単に利用することができ、また効率のよいストリーム処理も可能になるかもしれません。
おまけ: 高度な Tips
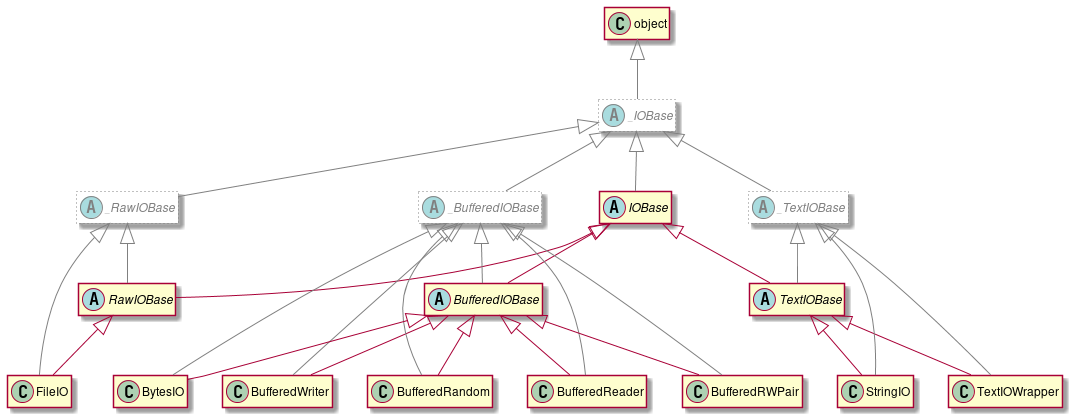
io と _io の関係について
CPython の場合 io モジュールのクラスは以下のように C 言語実装(_io モジュール)を使う形となっています。
ioモジュールの具象クラスは_ioモジュールのクラスをそのまま使う- クラス名が
_io.TextIOWrapperのように表示されるのはこのため
- クラス名が
ioモジュールのIOBaseのような 抽象基底クラス (ABC) は_ioモジュールのクラスを継承する- ABC の
registerメソッドを使うことで一部の継承関係を後付けする
下図の灰色の矢印が実際の(__bases__ や __mro__ で得られる)継承関係、赤い矢印が ABC によって後付けされた継承関係です。
Python の open 関数と open システムコールの対応
Python の open 関数は内部で os.open 関数を利用しており、これは open 系システムコール(以下 open(2) と記載)のラッパーとなっています 1 。Python の open の mode 引数と読み込み・書き込み権限に関するフラグとの対応は以下の通りです(CPython 実装を参照しています)。
Python の mode |
open(2) のフラグ |
|---|---|
r |
O_RDONLY |
w. a, x |
O_WRONLY |
r+, w+, a+, x+ |
O_RDWR |
ファイル存在時・非存在時の挙動に関するフラグとの対応は以下の通りです。
Python の mode |
open(2) のフラグ |
|---|---|
w |
O_CREAT | O_TRUNC |
a |
O_CREAT | O_APPEND |
x |
O_CREAT | O_EXCL |
その他の細かい挙動は以下の通りです。
- デフォルトではファイルディスクリプタを子プロセスへ継承させないためのフラグが付与される
- Linux 2.6.23 以降など
O_CLOEXECが利用できる場合は常に利用する - Windows の場合
O_NOINHERITを常に利用する
- Linux 2.6.23 以降など
- Windows の場合
O_BINARYが常に付与される- Python 側でテキストモードを指定した場合も OS レベルではバイナリモードを使用する
- Windows ではファイルパス引数としてワイド文字列を取る
_wopen関数が内部で使われる
他言語との比較
Python の I/O 関係のクラスを Java / Go のクラス・インターフェースと比較すると以下のようになります(あくまでざっくりとした比較であり言語によってインターフェースや内部実装はかなり異なります)。 Python のクラスは便宜上読み取り (R) / 書き込み (W) の機能別に分離しています。
| Python | Java | Go |
|---|---|---|
io.RawIOBase (R)io.BufferedIOBase (R) |
java.io.InputStream |
io.Reader |
io.RawIOBase (W)io.BufferedIOBase (W) |
java.io.OutputStream |
io.Writer |
io.FileIO (R) |
java.io.FileInputStreamjava.io.RandomAccessFile |
os.File |
io.FileIO (W) |
java.io.FileOutputStreamjava.io.RandomAccessFile |
os.File |
io.BufferedReader |
java.io.BufferedInputStream |
bufio.Reader |
io.BufferedWriter |
java.io.BufferedOutputStream |
bufio.Writer |
io.BytesIO (R) |
java.io.ByteArrayInputStream |
bytes.Buffer |
io.BytesIO (W) |
java.io.ByteArrayOutputStream |
bytes.Buffer |
io.TextIOBase (R) |
java.io.Reader |
- |
io.TextIOBase (W) |
java.io.Writer |
- |
io.TextWrapper (R) |
java.io.InputStreamReaderjava.io.Scanner |
bufio.Readerbufio.Scannertransform.Reader |
io.TextWrapper (W) |
java.io.OutputStreamWriter |
bufio.Writertransform.Writer |
io.StringIO (R) |
java.io.StringReader |
strings.Reader |
io.StringIO (W) |
java.io.StringWriter |
strings.Builder |
- Java や Go では基本的に読み取りに利用するクラス・インターフェースと書き込みに利用するクラス・インターフェースが分かれている
- Go ではテキスト I/O 専用のインターフェースはほぼ用意されていない
- Go の文字列 (
string) は任意のバイト列を保持する([]byteとの変換コストが低い)設計になっており Python, Java とは大きく異なる - 1 文字 (
rune) 毎に返すインターフェースとしてはio.RuneReaderが存在する transform.Writer/transform.Readerは golang.org/x/text/transform の interface であり、実際にはこれを実装した各エンコーディング毎の型を利用することになる
- Go の文字列 (
おわりに
今回は Python の open 関数と io モジュールについて解説しました。
open は入門書にも出てくるような基本的な関数ではありますが、細かい挙動を見ていくとかなり様々なことをやっているという印象で全体を理解するのはなかなか大変でした。
しかしながらこのような理解をしていなくてもなんとなく使えるようにもなっており、その意味では Python の設計の丁度よさ・割り切り方というのを感じ取ることもできました。
Python の公式リファレンスはかなり充実していおり、既に使っている機能でも読み返してみると新たな発見があります。 少しでも挙動が気になったら是非リファレンスに立ち返ってみましょう。
採用情報
朝日ネットでは新卒採用・キャリア採用を行っております。


- 厳密には libc の関数 open(3) を Python で利用するためのラッパーとなっており、glibc 等の内部実装では openat(2) システムコールが呼ばれている場合もあります。↩