
はじめに
こんにちは。朝日ネットでWebアプリケーションの開発を行っている tommy です。
昨年、BigQueryとTableauを使った、ちょっとした、社内データの分析環境を構築しました。
今回は、そのことについて書いていこうと思います。
概略
今回、構築した環境は以下のようになります。
- Goプログラムで社内から分析に必要なデータを収集し CSV化
- 1日1回、前項のCSVファイルを BigQuery に投入
- BigQuery のビューを定義しデータを整形
- Tableau から BigQuery のデータに Google スプレッドシート のデータを付与しつつ抽出
図にすると以下のような感じです。

我々のチームでは、データの収集・BigQueryへの投入・TableauからBigQueryのデータの抽出の定義作成 を担当し、Tableau での分析は他部署の人が行っています。
Google スプレッドシートは、データベースにはない集計用の付加情報をデータ分析者が追加できるようにするために利用しています。
BigQuery
BigQuery は Google 社が提供する大容量のデータを高速に分析することができるサービスです。
SQLが利用できるため、あたかも RDB のように利用することができます。
ただし、いわゆる RDB と違ってインデックスでデータを検索するのではなく、超並列でひとつひとつのデータを精査することにより大容量のデータの探索を実現する。という仕組みのため、ペタバイト級のデータでも高速に分析できるのに対し、簡単な検索に対してはインデックスが利くRDBでの検索 より遅いです。
よって、一般的なアプリケーションのDB として利用するのには不適となっています。
BigQuery の魅力はもちろん大容量データを高速で扱えるということもあるのですが、
- ディスク料金が非常に安い
- データを利用する手段が豊富 (REST API・いろいろなプログラミング言語のライブラリ・Cloud SDK の CLI ツール など)
- 使いやすい管理画面が提供されているのでちょっとデータの内容を調べるのが手軽にできる
といった利点があり1、分析の仕方が明確になっていなくてもとりあえず BigQuery にデータをためておくとあとから簡単に分析が始められるのでお勧めです2 。
多少、データの保存の仕方が汚くて分析しづらい状態になってしまったとしても、大容量データを高速で扱える BigQuery の力で強引にデータを整形することもできます。
料金について
BigQuery は 料金体系 がかなり独特になっており、大まかに
- ストレージ
- クエリ
- データのストリーミング挿入(使用する場合)
の3つに対してのみ課金が適用されます。
テーブルの作成/削除、及び(ストリーミング挿入を使わない)データの投入は課金対象にならず、テーブルを作ってデータ挿入して削除といった実験が気軽に行えるようになっています。
クエリに対する課金も独特で、クエリ内で利用したカラムの総容量が課金対象となり、 巨大なテーブルに対するクエリでも、1カラムしか利用しない場合クエリ料金は低くなります。 逆に、どんな絞り込み条件を書いてもLimit句で取得件数を絞っても、テーブル全体のクエリで使用したカラムの料金が請求されます3。 また、どんな複雑な判定式を書いたとしても1カラムのみの利用ならば課金対象は1カラム分のみです4。

Go プログラムからの BigQuery 利用
今回は Go のプログラムを作って、社内DBから必要な情報だけを抽出、 CSV に整形し BigQuery に投入しています5。
Go から BigQuery を利用する方法を簡単に説明すると、
- GCP コンソールの IAMと管理 からサービスアカウントを作成
- サービスアカウントの鍵を JSON で取得しファイルに保存
- 2 の JSON ファイルの場所を環境変数 GOOGLE_APPLICATION_CREDENTIALS で Goのプログラム に教える6
- あとは、Go の ライブラリ を使って bigquery を操作
テーブルのスキーマを、投入するCSVから自動判定してもらうこともできますが、それだとフィールド名や型が想定通りにならなかったりするので、あらかじめ作成しておきます。 今回は、Table.Create メソッドを用いてGoプログラムから作成するようにしました。
BigQuery へのデータ投入
Go プログラムから BigQuery を操作できるようになったら、実際に CSV を作成して投入していきます7。
プログラムで作成した CSV を、 Table.LoaderFrom メソッドを使って BigQuery にアップロードします8。
アップロードする際は CSV ファイルそのままでもいいですし、それを gzip 圧縮したものでも大丈夫です9。
今回アップロードしているファイルはそれほど大きくないのでそのまま Load していますが、ファイルサイズが大きい場合いったん Cloud Storage 上げてから Load したほうが取り込み速度が早いです。
一番苦労したのがこのアップロード用の CSV を作成するところでした。BigQuery はデータの型に厳密なので、少し変なデータがあるとデータの投入に失敗してしまいます。特に日時は形式が指定されており、さらに存在しない日時はエラーになります10。また、デフォルトだと改行を含む CSV はエラーとなってしまいます。(CSVOptions参照)
ビューの作成
アプリケーションのデータは、もちろん、分析するために保存してあるわけではないので、分析しやすくするために前処理と呼ばれる処理をする必要があります。
今回は、BigQuery の ビュー を定義することによって、この前処理のようなことを行いました11。
ビュー は SQL を定義しておき、その実行結果をあたかも一つのテーブルのように扱える機能です12。もちろん裏で SQL を実行しているだけなので ビュー で利用しているカラムも課金対象となります。
ビュー(クエリ) の実行結果からテーブルを作成する機能もあるので、分析のための中間テーブルを作成しておくことも容易にできます。

BigQuery と Tableau の連携
Tableau は Tableau Software社 が提供する有料のBI用のツールで、今回はこちらを利用してデータ分析を行いました14。
Tableau から BigQuery を利用するには
- Tableau 内の DB に指定した時間にすべてのデータを取得してきてそれを使ってグラフを表示する方法(抽出)
- グラフ描画の際毎回 BigQuery にクエリを投げる方法(ライブ)
の二種類が選べます。
2 だと、分析対象が大規模でも BigQuery の力を借りて表示できるメリットがありますが、表示条件をちょっと変えたりデータをフィルタしたり並び替えたりするだけで BigQuery にクエリが飛んでしまい料金がかさんでしまう恐れがあります。 また、前述のとおり RDB と違い絞り込み条件が単純でも少々の時間がかかってしまうため可能なかぎり前者を使ったほうが良いと思います15。
Tableau ではいろいろなデータソースからデータを"抽出"できます。 今回は、Google スプレッドシートのデータを BigQuery から抽出したデータに付与することでデータベースにはないけれど分析用に必要な情報 を付与することにしました16。
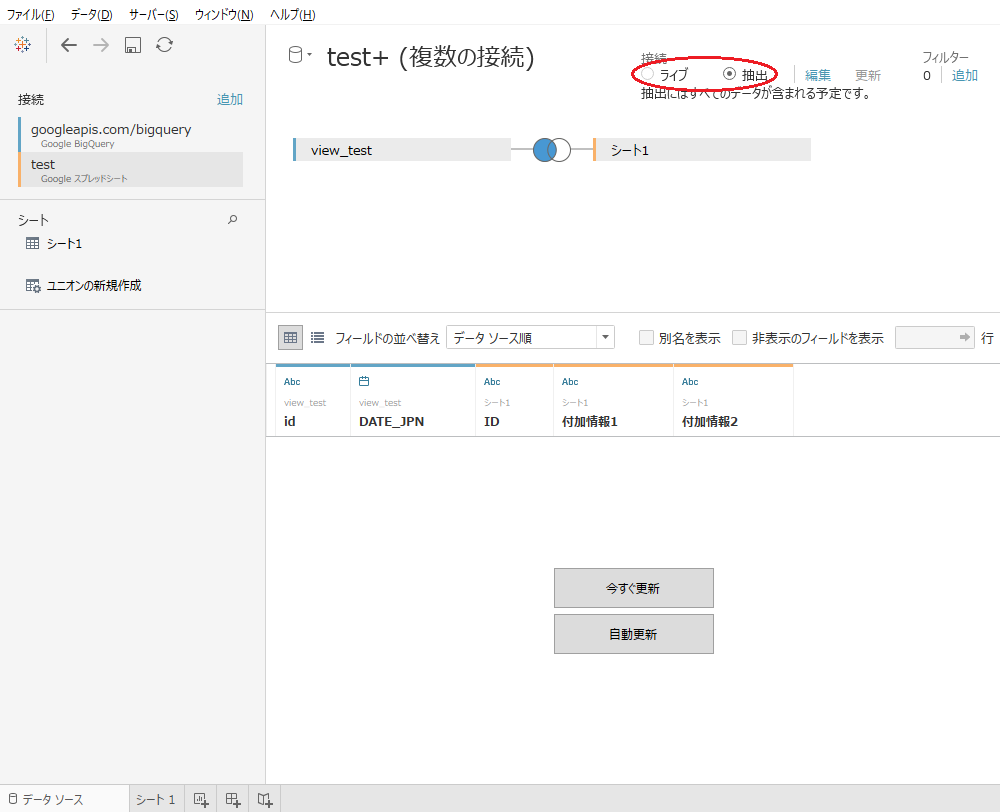
また、右上から前述のライブと抽出を選択することができる

課題
前述のとおり、スプレッドシートに付加情報を書いてもらうようにしたのですが、スプレッドシートへの記述間違い(一番多いのは同じデータを二回書いてしまうミス)がたびたび発生して、集計結果がおかしくなってしまう問題が発生しています。
また、このスプレッドシートの連結によりデータの抽出に非常に時間がかかるようになっており、Tableau側のデータソースの変更に手間がかかるようになってしまっています。
BigQueryとスプレッドシートの連結をTableauで直接行うのではなく、いったん前処理をかまして入力チェックなどを行う必要性を感じています。
おわりに
今回は、BigQuery とTableauでデータ分析環境を作った時の話を書いてみました。
BIツールでの可視化までいかなくても BigQuery にデータを投入しておくだけで、ちょっとデータ分析をしてみよう、と思ったときに簡単に始められるのでお勧めです。
BigQuery ML などにより、機械学習にかけてみたりすることまで手軽にできるようになってきました。
CSVファイルさえ用意すれば手動でアップロードして試して見ることもできるので、データ分析を考えているならば気軽に試してみることをお勧めします。
採用情報
朝日ネットでは新卒採用・キャリア採用を行っております。
-
今回扱ったデータは数GB程度でありビッグデータと呼べるほどのデータではなかったのですが、これらの利点から BigQuery を利用することにしました。↩
-
ただし、条件判定が複雑になればなるほど実行速度は遅くなってしまいます。↩
-
管理画面なども作成する必要があったため Go でプログラムを作成しましたが、すでに存在するログファイルなどから BigQuery にデータを投入するだけなら、Fluentd の BigQuery プラグイン を利用すれば簡単にデータ投入を始められます。↩
-
今回は人がExcelなどで利用することもあり、CSVで作成しましたが、CSV 以外にも JSON や Avro など、いくつかの形式がサポートされています。 ↩
-
一括でファイルを読み込む以外に ストリーミング挿入 という機能があります。こちらだと、データをAPIで投入するとすぐに検索可能状態になるというメリットがあります。ただし、こちらを使うとレコード1件ごとに一定額かかります。↩
-
ただし一度にアップロードできるファイルサイズの上限が 圧縮時 4GB, 非圧縮時 5TB という制限があります。↩
-
存在しない日時がデータとして存在すること自体がおかしいのですが、現実のデータとしてはそれなりに存在しました。それらのデータの扱いをどう扱うのが一番正しいのかを考えるのに頭を悩ませました。↩
-
GCP に前処理用のサービス Cloud Dataprep, Cloud Dataflow, Cloud Data Fusion などが存在します。今回は手軽に利用できる ビュー を使って前処理を行いましたが、機会があればこれらのサービスも触ってみたいと思っています。↩
-
一般的な RDB の View と同じです。↩
-
BIツールでそのまま TIMESTAMP 型を扱うとUTCになってしまうことが多かったので、このようなビューを作成したりしていました。↩
-
Google社が無料で提供しているデータスタジオ(現データポータル)の利用も考えたのですが、この時まだ機能が不十分であったこと、後述の、いわゆる “ライブ” でのグラフ表示しかできないこと、から見送りました。データポータルは現在も頻繁にアップデートがなされているので、当時とは状況が違うかもしれません。↩
-
データが大規模だとしても、データを前処理して分析対象期間を減らしたり、一部データを集計するなどして、データ量を減らして抽出するようにするのがいいと思います。↩
-
ただし、Google スプレッドシートのデータは BigQuery 内のデータではないので “抽出” に時間がかかるようになってしまいます。↩